
Two of our book readers and a book of songs
A quick glance at the bookshelves in the boys rooms and it looks like we have as many Chinese as we do books in English. Ethan can’t yet read in either language and yet he spends hours engrossed in books. One of the ways he’s able to do so is with assistance of smart pens or a small smart speaker (pictured above). In this case, ‘smart’ doesn’t mean internet connected, it doesn’t mean they have a screen. I use the term smart because of delightfully clever way they work.
Touch the pen to the page and it will read a word, sentence or even the full story. Touch the pen to the pictures and you get a sound effect or additional context to the story. These pens work offline and have hours of audio stored on device. Pick them up, touch them against the page and start reading. They come with hundreds of short stories, songs, sheet music, and science books.
I was curious how they worked and spent way longer than I should have finding out.
Observations
Reliability is rock solid. These things recognise pages correctly, in all lighting conditions, every time. Recognition is fast. It is difficult to identify a precise recognition time, but we hear audio well within a second of touching a page. Orientation has no effect on the reliability.
We have a few of these devices and they have subtle differences in how they work. One requires you to identify the book by touching the pen to a small designated area on the front cover. If you select one book and then try and use it on the pages from another then you get the wrong audio. The need to identify the book first, got me wondering if there was a limitation in the number of uniquely identifiable regions.
But the reader from another brand doesn’t require you to identify the book. You can jump from a page in one book to a page in another without issue. Could this decision to identify the book first be an implementation decision?
Visually the devices look different, but they all include an optical sensor embedded in the tip and what looked like an infrared LED for illumination. I assume this is a low resolution camera rather than a simple optical sensor.

A close up of a page. Note the fine dots on the surface.
Looking closely at the pages, you can make out a fine mesh of dots covering the surface. The dots appear to be placed with random variations from a regular grid. Instead of being placed at the intersection between horizontal and vertical lines on a grid, each dot is offset either to the north, south, east or west.
I was able to grab a macro shot on the phone and the dots are clearly visible. Stare at this long enough and you will start to see a pattern. I’m not sure if this is optical trickery at work or if these are genuine patterns, but I started to mark these out. Pink dots indicate the corners of repeating squares. Blue dots indicate a repeating cluster. The red horizontal and vertical lines. More on these later.

Look at the page long enough and patterns emerge.
How it works
It looks as though variation from the intersection points on a regular grid was being used to encode information.It wasn’t immediately clear whether variation from the intersection was purely directional or whether distance mattered. It doesn’t look as though there is sufficient variation to measure distance and I’ve made the assumption that information is encoded using directional variation alone.
It turns out that this method of encoding information in printed dots is most common in what is known as the Anoto dot pattern or Anoto encoding. Anoto Group is a Swedish company that makes amongst other things, digital pens.
“The Digital Pen is an ink pen combined with a digital camera that digitally records everything that is written. It works by recognizing a non-repeating dot pattern printed on the paper. The non-repeating nature of the pattern means that the pen is able to determine which page is being written on, and where on the page the pen is.”
The same technology is also used in learning toys such as the pens used to support reading.
The wikipedia entry for the Anoto dot pattern includes this helpful diagram. On the left we see the North, East, South, and West variations and a possible binary representation for the position. On the right we see a diagram that is not dissimilar to the image I captured of the page.
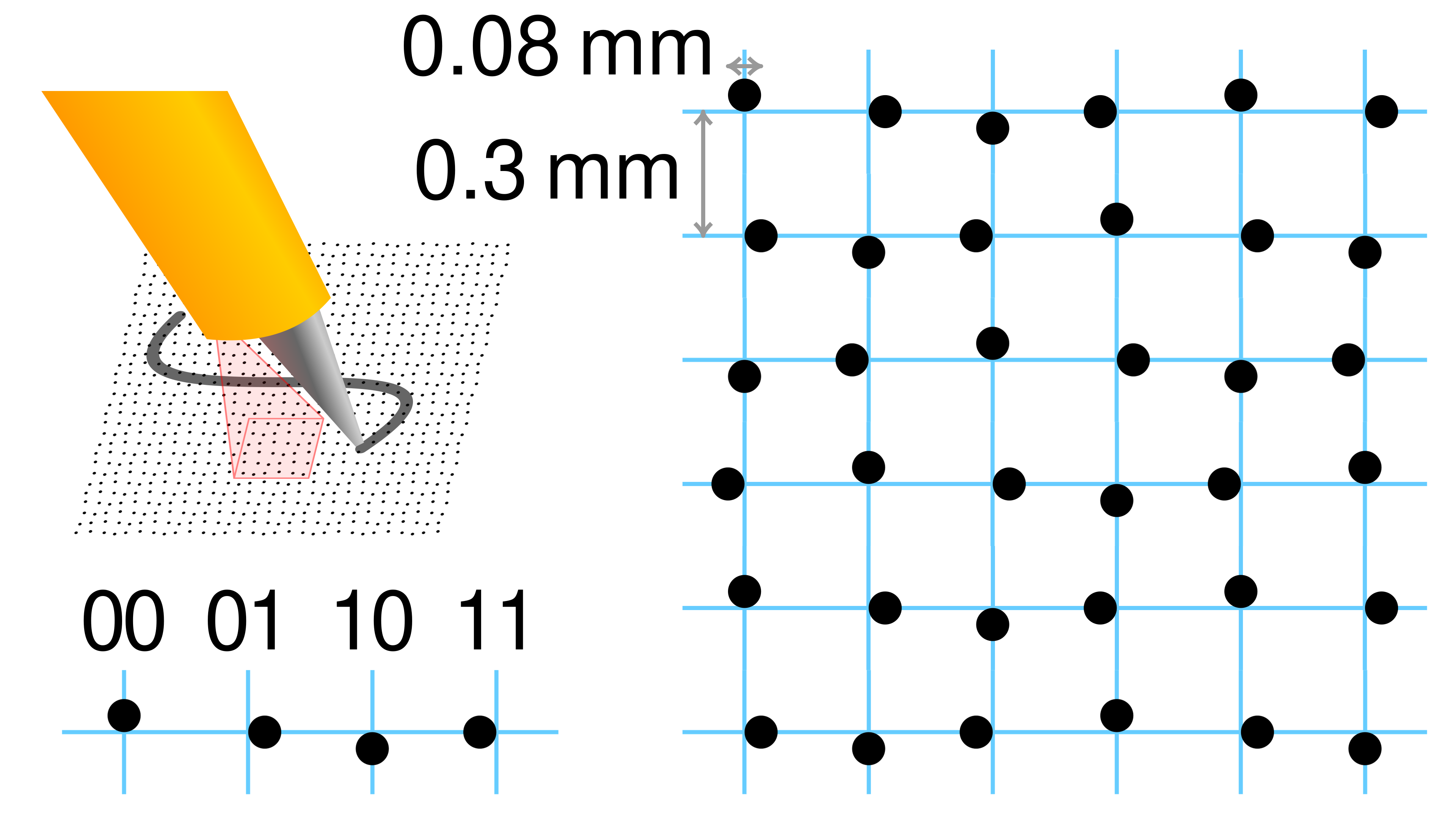
By Cmglee - Own work, CC BY-SA 4.0, Link
Now that we can interpret the dots, we need to use this information to determine our position on the page. The py-microdots library and the accompanying research paper, Position Encoding in the Euclidian Plane Using the Anoto Codec and pi-microdots by Christoph Heindl are an excellent resource for learning how this works.
But one claim stood out to me.
“The Anoto grid pattern encodes a unique 2D position for every possible 6x6 sub-array of dots. Assuming a grid resolution of 0.3mm, this coding remains unique over the area of Europe and Asia.”
Let’s assume that the area of Europe and Asia combined is 55,000,000 km².
At a dot spacing of 0.3mm that means we’d need more than a few dots.
For those who prefer words, 611,000,000,000,000,000,000 is six hundred eleven quintillion. A lot of dots.
To put that into perspective, a typical TV might have a display that is 60PPI or pixels per inch. Now I know we’ve been working in the metric system until now but people measure their TVs in inches.
At 60PPI, this would represent a 630 million inch TV. This is a screen area of 109 million square kilometres. You’d have to be on your way to the moon to sit at the recommended viewing angle for a TV this large.
How can a simple 2-bit dot encoding system (North, East, South, West) allow you to determine where you are on an area like this?
The Maths
If we look at an individual dot, we have only 2-bits of information to determine the {x, y} coordinates of the dot on an areas the size of Eurasia. 2-bits of information means our dot can be in one of four positions. This is not enough to uniquely determine our location in 611 quintillion dots. We need to use two mathematical tricks to get us there.
Trick 1 - 6x6 dots
For the first trick, we need to remember that the pen can see more than one dot at a time. In a typical implementation, the pen scans a 6x6 array of dots. This gives us 6 sequences of numbers along the x axis and 6 along the y axis.
Working through the first row in the diagram above we can use the table below to decode the sequence along the x axis. Note that there are two digits in the binary representation of the direction. We split these to give us a value in both the x and y axis.
| Direction | Binary | x axis | y axis |
|---|---|---|---|
| North | 00 |
0 |
0 |
| East | 01 |
0 |
1 |
| South | 10 |
1 |
0 |
| West | 11 |
1 |
1 |
The first row, NESWNE, becomes: 001100. The first column, NESWNE, becomes: 010101.
Expanding this out across the full 6x6 grid we end up with two matrices, one representing the 6 rows the other the six columns.
These strings of digits don’t give us a unique location just yet but they do give us more information to work with, 6 sequences of 6 bits in each direction.
Trick 2 - The de Bruijn Sequence
A de Bruijn sequence is a circular string where every possible pattern of a given length appears exactly once. This might make more sense with an example.
For binary with length 2 the de Bruijn sequence is: 0011.
In this sequence we get the following strings of length two.
00011110
These are all possible patterns for a string of 1s and 0s that has a length of 2. Each one appears once in the sequence.
If we know the sequence, we can uniquely determine the location of any string of length 2. For example: 11 occurs at position 2 (starting at 0), and 10 occurs at position 3.
With length 2, we don’t have much more information than we had from looking at a single dot. Where the de Bruijn sequences become useful is how quickly they scale up as the length of the string increases.
The formula for determining the length of the de Bruijn sequence is show below.
Here is the size of your alphabet, or the number of possible characters you have. For us this is 2 because we have the characters 0 and 1. The length of our string gives us the value for . For the example above we can determine the length of the sequence as follows.
If you remember the de Bruijn sequence from before, it was 0011 which is indeed length 4. Applying this to our dot pattern, our alphabet or value remains 2 but we have 6 dots giving us an of 6.
This means that by scanning a sequence of 6 dots we can determine our unique position in one of 64 unique positions. Remember that we can do this in both the x and the y axis. Looking at one row and one column we might come up with the location as in the diagram below.
sequence_1.png
But knowing where we are on a 64x64 grid at a pitch of 0.3mm gives us an area of just over 3.5 cm². Not nearly enough to cover the surface of Europe and Asia.
Trick 3 - Sequence within a sequence
The third trick at play expands on the fact that we can see a 6x6 array of dots and combines it with another de Bruijn sequence.
sequence_2.png
We looked at how the sequence for the first row of dots 100110 might occur at position 4 in a de Bruijn sequence of length 64. We can repeat this for rows 2 through 6. The second row might occur at position 7, the third at position 3 and so on.
This gives us new sequence, 4, 7, 3, 1, 7, 2. What if this was part of another de Bruijn sequence. This time each character in the sequence, our , could have one of 64 different values. The value for remains at 6. The length of this new sequence can be calculated as follows.
The same approach works for the y axis. This gives us the ability to locate where we are over an incredible area.
In words that would be the ability to locate where we are in a grid of 4.72 sextillion dots. This is an order of magnitude more than the 611 quintillion that we would need to cover an area the size of Eurasia.
Incredible!
Those visible patterns
Looking back at the macro shot of the page and my attempts to mark out repeating patterns, I realise that I haven’t grasped the full picture.
- There appear to be clusters of 4x4 dots rather than 6x6
- Lines with no x or y variation
- I’ve focused on finding location, but the way the books are laid out we only need to identify areas on a page.
My current assumption is that a smaller cluster of 4x4 dots is used because we don’t need to cover an area the size of Eurasia. With a 4x4 cluster we can only cover a just under 387m² but this is more than enough for a few hundred Childrens books. I assume the regular lines without variation in the x and y axis are used to determine the orientation of the page. I would imagine this reduce the number of bits we have available for positioning.
Area encoding is harder. This stumped me until I looked again at the page I used to capture the macro shot. The page used in the photo was for a song. Tapping anywhere on the page played the song. It would make sense then that we didn’t need to know the precise location on the page, we needed a code that was unique to that page. A repeating pattern of 4x4 dots would give us just that. The pen would then need to map the code represented by that location to an audio track.
It is reasonable to expect that variations on this scheme can be used depending on the use case but it is incredible how something as simple as being able to determine whether a dot is offset to the North, East, South, or West of a point can be used to determine your location on an area the size of Eurasia.
At this point, I think I’ve gone far enough down the rabbit hole. It has been fun. But the reason I started to write this blog post was originally the ecosystem behind the various systems.
The Ecosystem
We have devices and books from both Chinese and American brands. The differences between them are astounding.
The Chinese devices come pre-loaded with audio for the complete range of books. They are self contained. The manufacturer could vanish tomorrow and the pen would carry on functioning. No network connectivity required, no need to phone home, create an account, or track progress.
The pen from an American brand has a subset of available audio and constantly asks you to connect to the app, and presumably take out a subscription to load audio from other books in the series. The desire for recurring revenue overrides the experience of a child using the device. Instead of being able to pick up a book and continue to explore, they are tied to their parent, an account, and a corporation every time they want to try something new.
We haven’t created an account and the pen sits idle. If we had, we’d have been asked to agree to their privacy policy. Which contains the following.
Information That Is Automatically Collected:
We also may collect certain information automatically when parents or children use the Services, including:
- Usage data that shows how parents and children use and interact with the Services across their devices, including information about how your child performs and progresses on activities when using the Services (such as play duration, correct answers, etc.);
- Child’s wish list selections, if a parent has authorized the child’s access to the LeapFrog App Center from certain Services;
- Your browser type and operating system, sites you visited before and after visiting the Services, information about the device you use, the links you click, and the pages you view within the Services, connection date, and other server log information;
- Account and order identifiers, order history of the products that you purchase or download online;
- Persistent identifiers, such as LeapFrog device identification numbers and your Internet Protocol (IP) address, which is the number automatically assigned to your computer or device whenever you access the Internet and that can sometimes be used to derive your general geographic area;
In addition to that there is a whole heap of personally identifiable information about the child “that parents may provide”.
If that wasn’t enough the privacy policy continues.
“We also may obtain additional data, or enhance, update, or add to our existing records with information we acquire from third-party sources, such as data aggregators and third party promotional partners. When parents access third-party services, such as Facebook or Twitter, through the Services to share information about the Services with others, we may collect information from these third-party services.”
Which would you buy?
References
- Position Encoding in the Euclidean Plane Using the Anoto Codec and py-microdots, Christoph Heindl
- py-microdots, Christoph Heindl
- De Bruijn, Wikipedia
- Acknowledgement of priority to C. Flye Sainte-Marie on the counting of circular arrangements of $2^n$ zeros and ones that show each n-letter word exactly once (pdf), N.G. de Bruijn
- Cellulo: Tangible Haptic Swarm Robots for Learning, Ayberk Özgür
- Anoto, Wikipedia